-
[HIVE SQL] 코딩테스트 준비 1SQL 배우기 2023. 5. 20. 11:26
- 사칙 연산시 NULL값 주의하기
- 또는 비율을 계산할 때, 정수로 나누거나 0으로 나누는 등의 실수를 할 수 있다.
NULL은 문자와 결합해도, 숫자와 사칙연산을 해도 NULL이 된다. 따라서 원하는 결과 형태에 따라 처리 후 가공해야 한다.
예를 들면, (금액 - 할인금액) = 만 원-NULL = NULL 이러면 안되는 거잖아!
따라서 만 원 - COALESCE(할인금액, 0) = 만 원 이렇게 처리해야 한다.
또는 NULLIF 를 사용한다.
계산한 값이 소수점을 포함하려면 100.0 * 컬럼 이런 식으로 사용하자
- SIGN 함수는 매개변수가 양수면 1, 0이라면 0, 음수라면 -1을 리턴한다.
평균을 낼 때, NULL값을 같이 카운트할지, 빼고 카운트할지에 따라 활용하면 된다.
- 거리 계산
제곱은 POWER, 제곱근은 SQRT ,ABS 절댓값 → sqrt(power(x1-x2,2)) as rms
- 날짜, 시간 계산 함수
to_date() 타임스탬프 문자열을 날짜로 변환할 때
date_add(to_date(), 1) : after 1 day
add_months(to_date(),-1) : before 1 month
datediff( , ) : 두 날짜의 차이를 계산
- 문자열 다루기
split함수로 문자열을 분해하고 n번쨰 요소 추출하기
이때 피리어드(점)가 특수 문자이므로 역 슬래시로 이스케이프 처리해야 함
ip : 192.168.0.1 → cast(split( ip, '\\.')[0] as int) : 192
- 집약 함수를 적용한 값과 집약 전의 값을 동시에 다루기
윈도우 함수에서 over 구문에 매개변수를 지정하지 않으면 테이블 전체에 집약함수를 적용한 값이 리턴된다.
partition by (컬럼) 을 지정하면 해당 컬럼 값을 기반으로 그룹화하고 집약 함수를 적용한다.
따라서 원래 레코드를 건드리지 않고 추가할 수 있다.
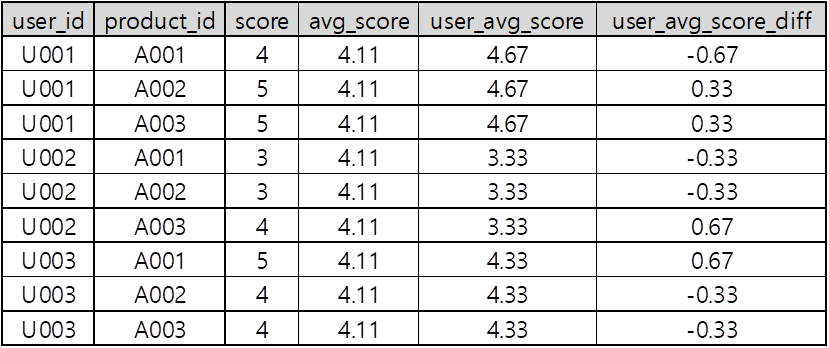
select user_id, product_id
, score : 개별 리뷰 점수
, avg(score) over() as avg_score : 전체 평균 리뷰 점수
, avg(score) over(partition by user_id) as user_avg_score : 사용자의 평균 리뷰 점수
, score - avg(score) over(partition by user_id) as user_avg_score_diff : 개별 리뷰 점수와 사용자 평균 리뷰 점수 차이
- LAG, LEAD
lag(product_id, 2) over(order by score desc) : 현재 행보다 앞에 있는 행의 값 추출하기
lead(product_id, 2) over(order by score desc) : 현재 행보다 뒤에 있는 행의 값 추출하기
- FIRST_VALUE, LAST_VALUE 순위가 높은, 낮은 상품 id 찾기
order by 구문과 sum/avg 등의 집약함수를 조합하면, 집약 함수의 적용 범위를 유연하게 지정할 수 있음.
order by 구문에 이어지는 rows 구문은 이후에 설명할 윈도우 프레임 지정 구문임
select product_id, score
, row_number() over(order by score desc) as row
, sum(score) over(order by score desc rows between unbounded preceding and current row) as cum_score : 순위 상위에서 현재 행까지의 스코어를 모두 더한 값
, avg(score) over(order by score desc rows between 1 preceding and 1 following) as local_avg : 현재 행과 앞뒤의 행 하나씩, 전체 3개 행의 평균 스코어를 계산한 값
, first_value(product_id) over(order by score desc rows between unbounded preceding and unbounded following) as first_value : 윈도우 내부의 가장 첫 번째 레코드 추출
, last_value(product_id) over(order by score desc rows between unbounded preceding and unbounded following) as last_value : 윈도우 내부의 가장 마지막 레코드 추출
위처럼 윈도우 프레임 지정하는 법
가장 기본 : ROWS BETWEEN start AND end
start / end : CURRENT ROW(현재의 행), n PRECEDING(n행 앞), n FOLLOWING(n행 뒤), UNBOUNDED PRECEDING(이후 행 전부) 등
- 윈도우 프레임 지정별 상품ID 집약 배열하는 쿼리
select product_id
, row_number() over(order by score desc) as row
, collect_list(product_id) over(order by score desc rows between unbounded preceding and unbounded following)
: 가장 앞 순위부터 가장 뒷 순위까지의 번위를 대상으로 상품 ID 집약
, collect_list(product_id) over(order by score desc rows between unbounded preceding and current row)
: 가장 앞 순위부터 현재 순위까지의 범위를 대상으로 상품 ID 집약
, collect_list(product_id) over(order by score desc rows between 1 preceding and 1 following)
: 순위 하나 앞과 하나 뒤까지의 범위를 대상으로 상품 ID 집약
'SQL 배우기' 카테고리의 다른 글
[SQL] SQL 명령 특성에 따른 구분 DDL DML DCL (0) 2023.11.24 [HIVE SQL] 코딩테스트 준비 2 (0) 2023.05.21 [HIVE SQL] 내장함수(Bulit-in Function) 확인하기 + 파이썬은 덤 (0) 2023.03.27 행과 행의 관계를 쉽게 계산해주는 윈도우 함수 Window Function [SQL] (0) 2023.03.18 Array 관련된 기본적인 함수 익히기 Hive sql (0) 2023.03.04