-
[Do it 자연어 처리] 1일차 자연어 처리, 트랜스퍼 러닝의 개념머신러닝 배우기 2023. 9. 30. 01:32
NLP 의 역할
: 문서 분류, 기계 독해, 문장 생성, 요약 및 번역, 감정 분석, 자연어 추론, 개체명 인식, 질의 응갑, 문장 생성
NLP 언어 모델 종류
: BERT, GPT 등
NLP 기법
: 트랜스포머, 전이학습, CNN(콘볼루션 신경망), RNN(순환 신경망) 등
모델의 뜻
: 입력을 받아 어떤 처리를 수행하는 함수
: 입력 → 모델(함수) → 출력(확률)
자연어처리 모델의 정의
: 자연어를 입력박아서 해당 입력이 특정 범주일 확률을 반환하는 확률 함수
학습의 뜻
: 출력이 정답에 가까워지도록 모델을 업데이트하는 과정
자연어 처리 모델 종류 : 트랜스퍼러닝 등
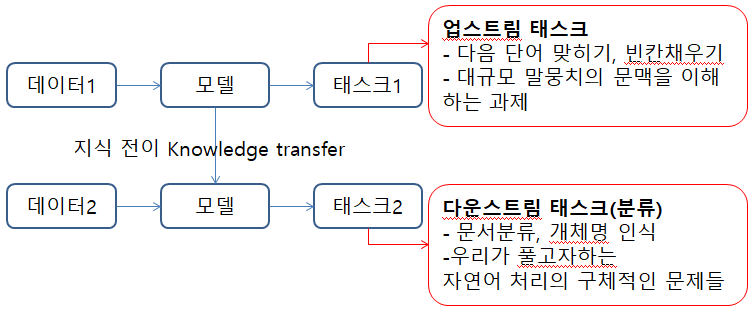
트랜스퍼러닝이란 ?
: 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법
트랜스퍼러닝의 장점
: 기존보다 모델의 학습 속도가 빨라지고 새로운 태스크를 더 잘 수행한다
트랜스퍼러닝의 방식
: 자연어의 풍부한 문맥을 모델에 내재화하고 이 모델을 다양한 다운스트랑 태스크에 적용해 성능을 끌어올리기
프리트레인이란 : 업스트림태스트를 학습하는 과정 (다운스트림 태스크를 수행하기 전단계)
언어모델이란 : 다음 단어 말하기로 업스트일 태스크를 수행한 모델
마스크 언어모델이란 : 빈칸채우기로 업스트림 태스크를 수행한 모델
업스트림 태스크의 대표 과제 : 다음 단어 맞추기, 빈칸 단어 채우기
지도학습이란 ?
: 정답이 있는 데이터로 모델을 학습시키는 방법
지도학습의 단점
: 데이터를 만드는데 비용과 시간이 많이 듦. 실수로 잘못된 레이블을 줄 수 있음
자기지도학습이란 ?
: 데이터 내에서 정답을 만들고 이를 바탕으로 모델을 학습하는 방법
자기지도학습의 장점
: 뉴스, 웹문서, 백과사전 등 글만 있으면 수작업 없이도 다량의 학습데이터를 싼값에 만들 수 있음
자기지도학습의 효과
: 업스트림 태스크를 수행한 모델은 성능이 기존보다 우수해짐
다운스트림 태스크의 본질
: 자연어를 입력받아 해당 입력이 어떤 범주에 해당하는지 확률형태로 변환하여 분류하는 것
다운스트림 태스크의 학습 방식
: 파인 튜닝, 프롬프트튜닝, 인컨텍스트 러닝
1. 파인튜닝
다운스트림 태스크 데이터 전체를 사용한다.
다운스트림 데이터에 맞게 모델 전체를 업데이트한다.
2. 프롬프트튜닝
다운스트림 태스크 데이터 전체를 사용한다.
다운스트림 데이터에 맞게 모델 일부만 업데이트한다.
3. 인컨텍스트러닝
다운스트림 태스크 데이터 일부만 사용한다.
다운스트림 데이터에 맞게 모델 업데이트하지 않는다.
모델을 업데이트하지 않고 다운스트림 태스크를 바로 수행할 수 있는 것은 큰 장점이다
인컨텍스트러닝 방식에는 제로샷 러닝, 원샷 러닝, 퓨샷 러닝 3가지가 있다
- 제로샷 러닝 : 다운스트림 태스크 데이터를 전혀 사용하지 않음. 모델이 바로 다운스트림 태스크를 수행
- 원샷 러닝 : 다운스트림 태스크 데이터를 1건만 사용. 모델은 1건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크 수행
- 퓨샷 러닝 : 다운스트림 태스크 데이터를 몇 건만 사용. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크 수행
학습 파이프라인
1. 각종 설정값 정하기
2. 데이터 내려받기
3. 프리트레인을 마친 모델 준비하기
- 모델 생성시 필요한 설정값 (프리트레인 모델 종류, 학습 데이터, 학습 결과 저장 위치 등)
- 하이퍼 파라미터란 모델 구조와 학습 등에 직접 관계된 설정값을 의미. 종류는 러닝레이트나 배치 크기 등이 있다
4. 토크나이저 준비하기
- 정의 : 토큰화를 수행하는 프로그램
- 한국어 종류 예시 : 은전한닢(mecab), 꼬꼬마(kkma)
5. 데이터 로더 준비하기
- 컬레이트 : 배치의 모양 등을 정비해 모델의 최종 입력으로 만들어주는 과정
- 인덱싱 : 각 토큰을 그에 해당하는 정수로 변환하는 과정 (보통 토크나이저가 토큰화와 함께 수행함)
6. 태스크 정의하기
7. 모델 학습하기
→ 태스크 학습과정 : 최적화해서 모델 만들고 입력값을 넣어서 출력하는 것 반복
파이토치 : 딥러닝 모델을 쉽게 다룰 수 있도록 하는 파이썬 라이브러리
토큰
- 정의 : 문장보다 작은 단위
- 분리 기준 특징 : 그때그때 다름. 문장을 띄어쓰기로 나눌 수도, 의미의 최소 단위인 형태소 단위로 나눌 수도 있음
토큰화
- 정의 : 토큰 시퀀스로 분석하는 과정
- 방법 : 수행대상에 따라 문자, 단어, 서브워드로 나눌 수 있다.
- 문자로 나눌 때의 장단점 : 한글, 알파벳, 숫자, 기호 등을 어휘 집합의 크기는 1.5만 개 정도밖에 되지 않음. 모든 문자를 어휘 집합에 포함하므로 신조어 등의 어휘 집합에 없는 토큰을 갖지 사실상 불가능. 하지만 각 문자 토큰은 의미있는 단위가 되기 어려움. 예를 들어 어제의 어와 어미 어의 구분이 사라짐. 또한 앞의 단어 단위와 비교할 때 분석 결과인 토큰 시퀀스의 길이가 상대적으로 길어졌음을 확인할 수 있음. 언어 모델에 입력할 토큰 시퀀스가 길면 모델이 해당 문장을 학습하기 어렵고 결과적으로 성능이 떨어지게 됨
- 단어로 나눌 때의 장단점 : 단어(어절) 단위로 분리하는 것. 예를 들어 공백으로 분리. 그러면 특별한 토크나이저를 쓰지 않아도 되는 장점이 있지만, 어휘 집합의 크기가 매우 커질 수 있음. 갔었어, 갔었는데요 처럼 표현이 살짝만 바뀌어도 모든 경우의 수가 어휘 집합에 포함돼야 함
- 서브워드로 나눌 때의 장단점 : 단어와 문자 단위 토큰화의 중간에 있는 형태인데, 어휘 집합 크기가 지나치게 커지지 않으면서 미등록 토큰 문제를 피하고, 분석된 토큰 시퀀스가 너무 길어지지 않게 함. 대표적인 기법에는 바이트 페어 인코딩이 있음
참조 : Do it! BERT와 GPT로 배우는 자연어 처리 (이기창, 이지스퍼블리싱(주))
'머신러닝 배우기' 카테고리의 다른 글
[머신러닝] Cross-validation으로 과적합 피하기 (K-Fold CV) (1) 2023.12.05 [머신러닝] 쉽게 설명하는 머신러닝 (1) 2023.12.04 데이터 분석하는데 선형대수를 왜 공부해야해? 에 대한 답변 (1) 2023.12.04 [머신러닝] feature importance 의 특징과 장단점 (1) 2023.12.04 [통계] 상관계수 총정리! 피어슨과 스피어만 상관계수 차이 비교 (0) 2023.11.27